Hi Pythonistas!
Today we will learn about a Python package called tablib. Tablib is a Python library that provides a unified and consistent interface for working with tabular data in various formats, such as CSV, Excel, JSON, and more. It allows you to easily import, export, manipulate, and organize data in a convenient and efficient manner. Whether dealing with simple data sets or complex spreadsheets, Tablib can help you maintain data integrity and simplify your workflow.
Let us dive into the code
Installation
pip install tablibCreating dataset
import tablib
dataset = tablib.Dataset()
dataset.headers = ['Name', 'Age', 'City']
dataset.append(['Guido Van Rosum', 67, 'Harlem'])
dataset.append(['Sourav Ganguly', 51, 'Behala'])
dataset.append(['Dhoni', 42, 'Ranchi'])
print(dataset)Output
Name |Age|City
---------------|---|------
Guido Van Rosum|67 |Harlem
Sourav Ganguly |51 |Behala
Dhoni |42 |RanchiExport data as csv
with open('data.csv', 'w') as f:
f.write(dataset.csv)As csv file with this data is created.
Load data from a csv
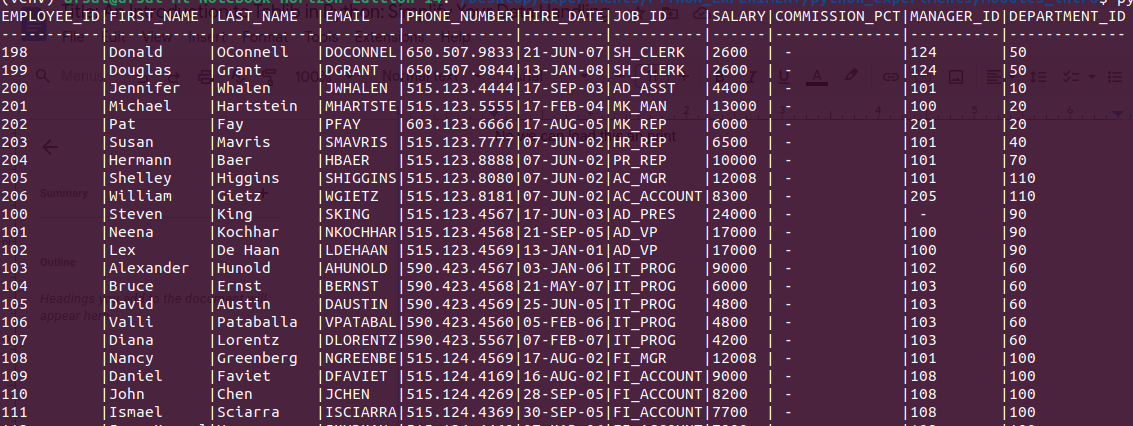
I have created a csv from this link which contains employee data, Now we can load and an print
with open('employee.csv', 'r') as f:
dataset = tablib.Dataset().load(f.read(), format='csv')
print(dataset)Output
In this post we have learned only the basics in the upcoming post we will learn about data manipulation like sorting, filtering etc.
Please share your valuable suggestions with afsal@parseltongue.co.in